
Publications
Full publication list in [Google Scholar]
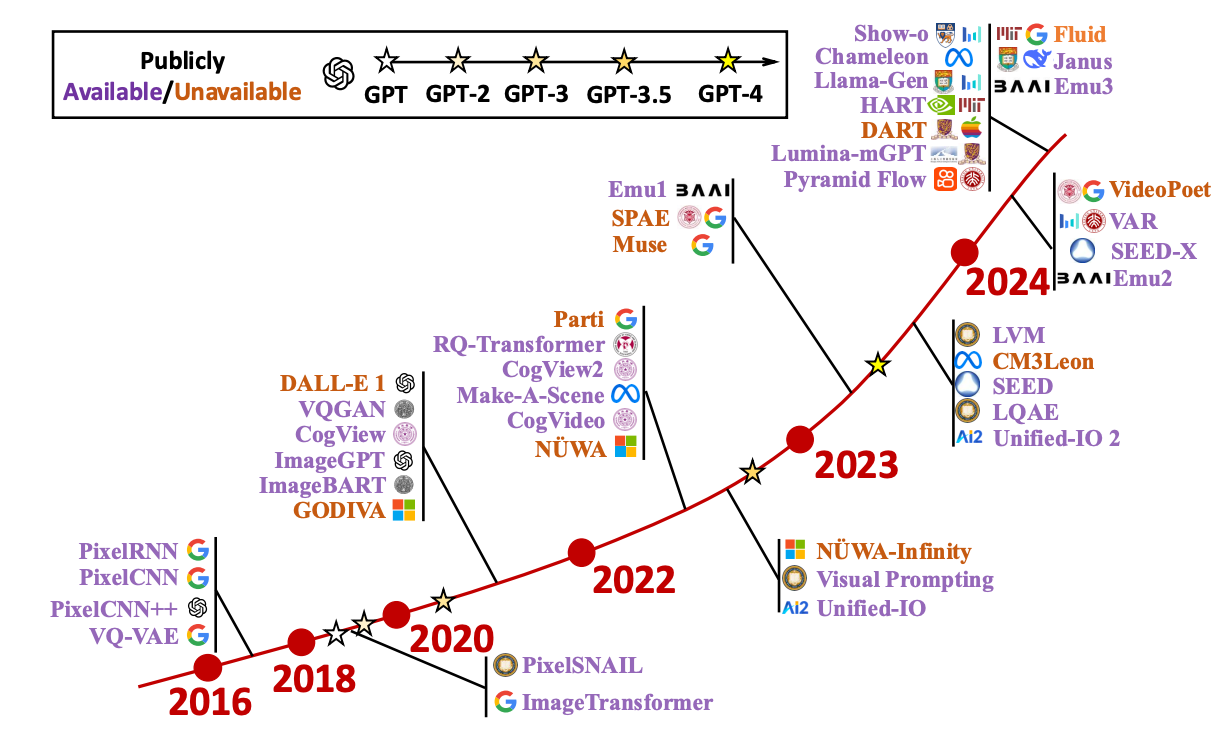 Jing Xiong, Gongye Liu, Lun Huang, Chengyue Wu, Taiqiang Wu, Yao Mu, Yuan Yao, Hui Shen, Zhongwei Wan, Jinfa Huang, Chaofan Tao $\ddagger$, Shen Yan, Huaxiu Yao, Lingpeng Kong, Hongxia Yang, Mi Zhang, Guillermo Sapiro, Jiebo Luo, Ping Luo, Ngai Wong [PDF], [Code], TL,DR: We provide a comprehensive and timely literature review of visual autoregressive models. We divide the fundamental frameworks based on the representation strategy of the visual sequence. Then we explore the applications in computer vision, including image generation, video generation, 3D generation, multi-modality, and the emerging domains such as embodied AI and 3D medical AI.
Jing Xiong, Gongye Liu, Lun Huang, Chengyue Wu, Taiqiang Wu, Yao Mu, Yuan Yao, Hui Shen, Zhongwei Wan, Jinfa Huang, Chaofan Tao $\ddagger$, Shen Yan, Huaxiu Yao, Lingpeng Kong, Hongxia Yang, Mi Zhang, Guillermo Sapiro, Jiebo Luo, Ping Luo, Ngai Wong [PDF], [Code], TL,DR: We provide a comprehensive and timely literature review of visual autoregressive models. We divide the fundamental frameworks based on the representation strategy of the visual sequence. Then we explore the applications in computer vision, including image generation, video generation, 3D generation, multi-modality, and the emerging domains such as embodied AI and 3D medical AI.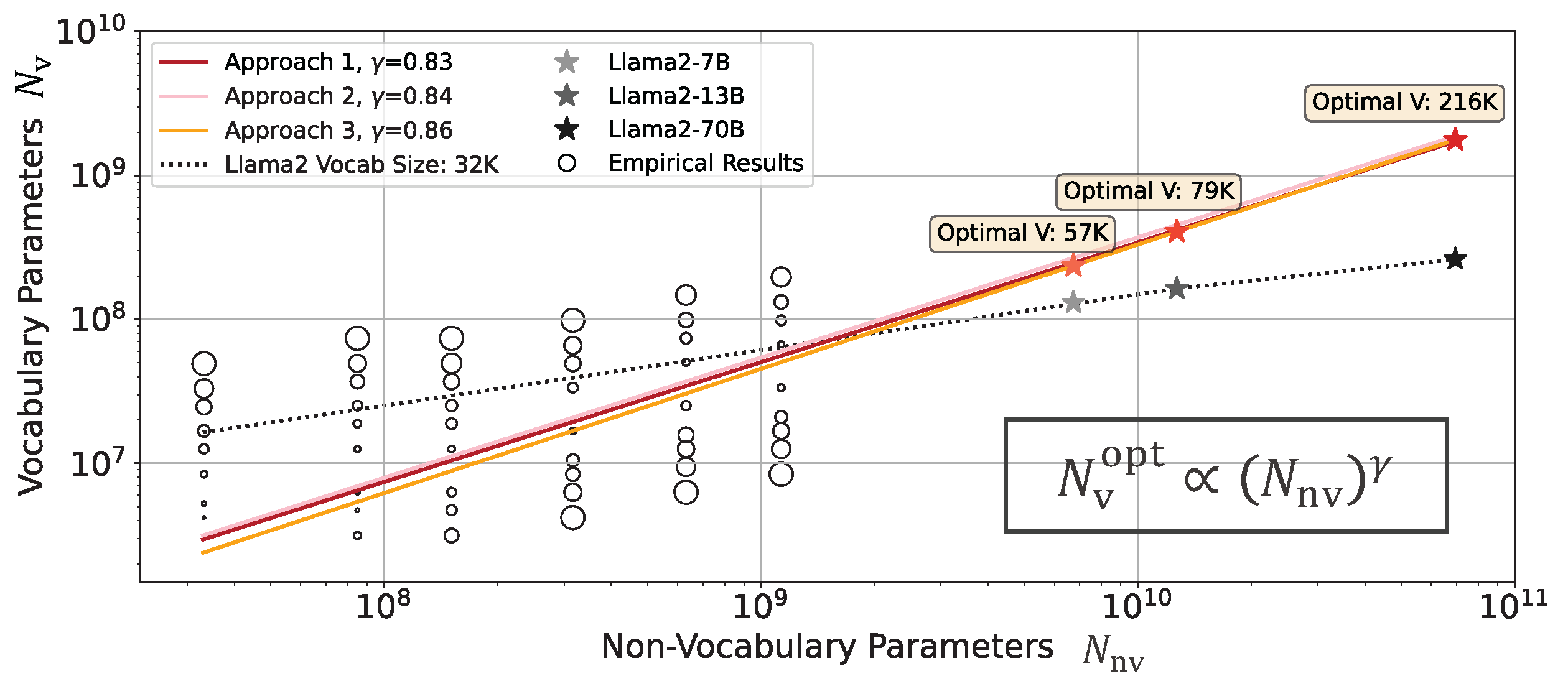
Chaofan Tao, Qian Liu, Longxu Dou, Niklas Muennighoff, Zhongwei Wan, Ping Luo, Min Lin, Ngai Wong. Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies, NeurIPS-2024 [PDF], [Code], [Demo], [Slide], TL,DR: This paper investigates models with different vocabularies, substantiating a scaling law that optimizes computational resources with the consideration of vocabulary and other attributes jointly.
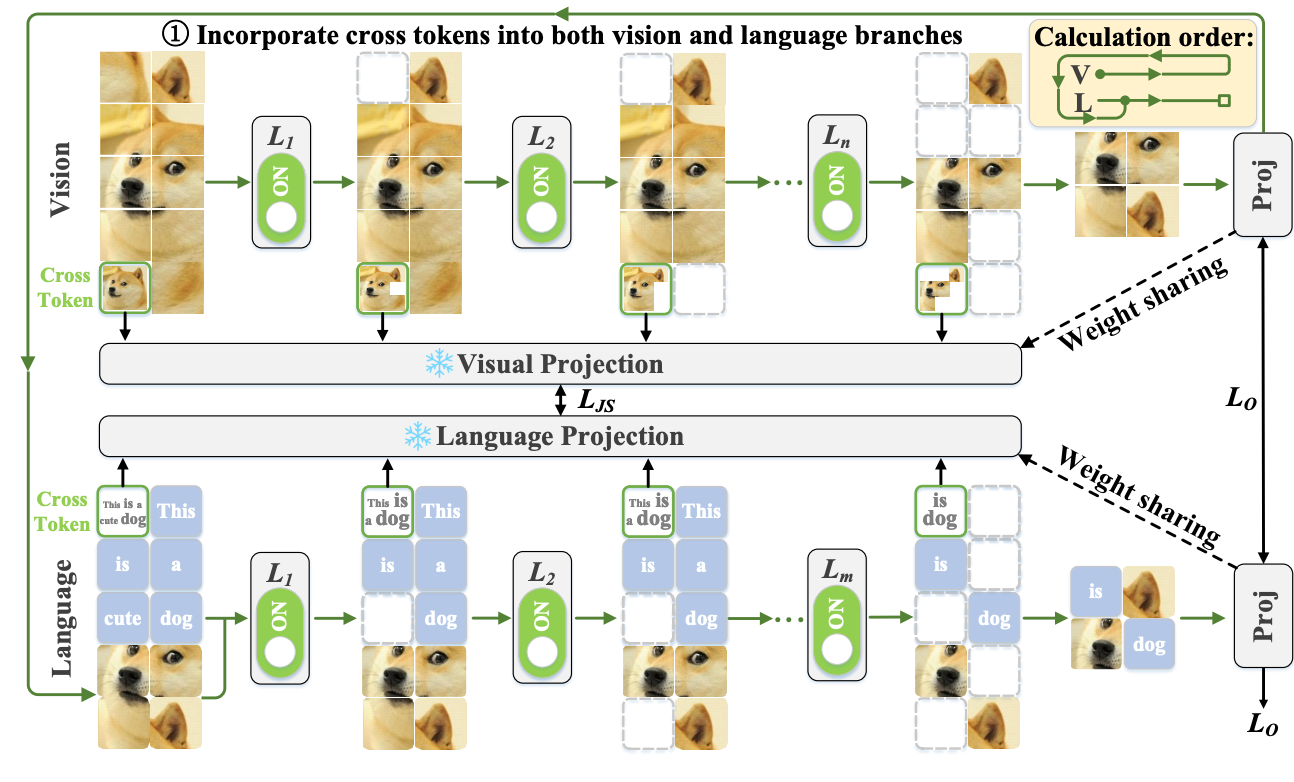
Dachuan Shi, Chaofan Tao, Anyi Rao, Zhendong Yang, Chun Yuan, Jiaqi Wang. CrossGET: Cross-Guided Ensemble of Tokens for Accelerating Vision-Language Transformers, ICML-2024 [PDF], [Code], TL,DR: CrossGET is a general acceleration framework for vision-language Transformers. This framework adaptively combines tokens in real-time during inference, significantly reducing computational costs.
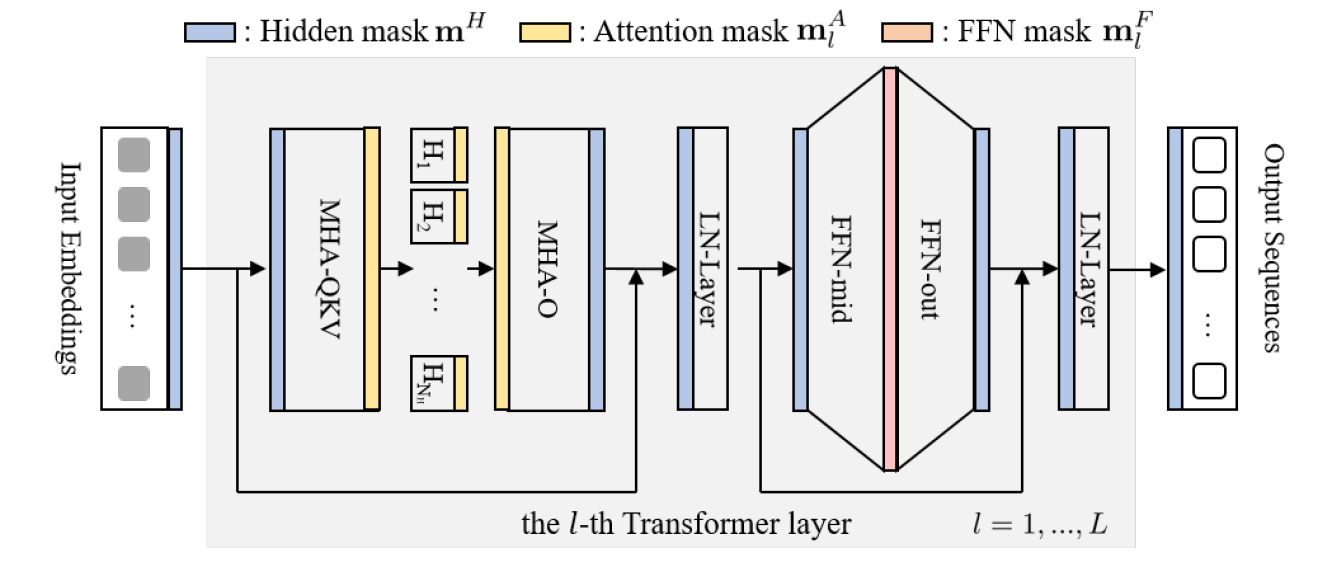
Chaofan Tao, Lu Hou, Haoli Bai, Jiansheng Wei, Xin Jiang, Qun Liu, Ping Luo, Ngai Wong. Structured Pruning for Efficient Generative Pre-trained Language Models, Findings of ACL-2023 [PDF], TL,DR: We propose a multi-dimensional structured pruning framework, SIMPLE, for generative PLMs (i.e. GPT-2, BART), which can also be easily extended to block pruning and unstructured pruning.
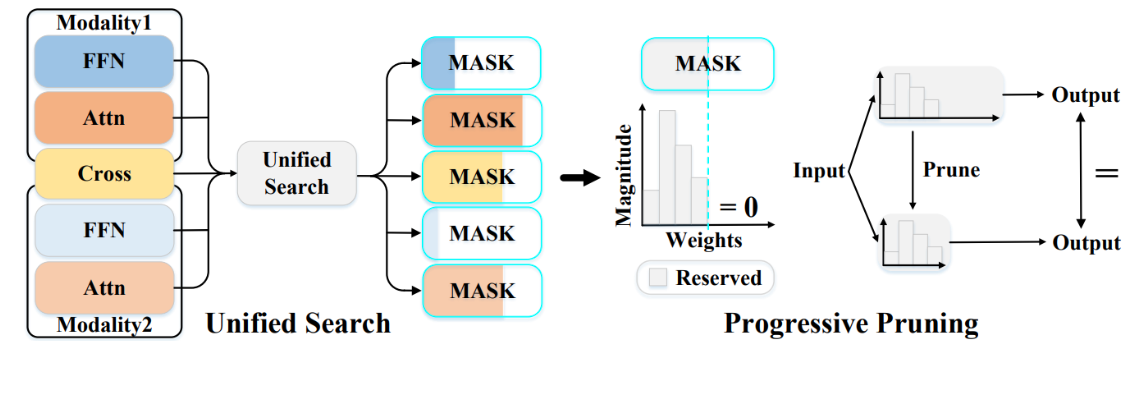
Dachuan Shi, Chaofan Tao, Ying Jin, Zhendong Yang, Chun Yuan, Jiaqi Wang. Upop: Unified and Progressive Pruning for Compressing Vision-Language Transformers, ICML-2023 [PDF], [Code], [Project], TL,DR: UPop is the first structured pruning framework for vision-language Transformers. It enables effective structured pruning on various multi-modal & uni-modal tasks, datasets, and model architectures.

Dongsheng Chen, Chaofan Tao, Lu Hou, Lifeng Shang, Xin Jiang, Qun Liu. LiteVL: Efficient Video-Language Learning with Enhanced Spatial-Temporal Modeling, EMNLP-2022 [PDF], TL,DR: We achieve SOTA video-language performance on text-video retrieval/videoQA, without any video-language pre-training, based on a simple-yet-effective adaptation from a pre-trained image-language model.
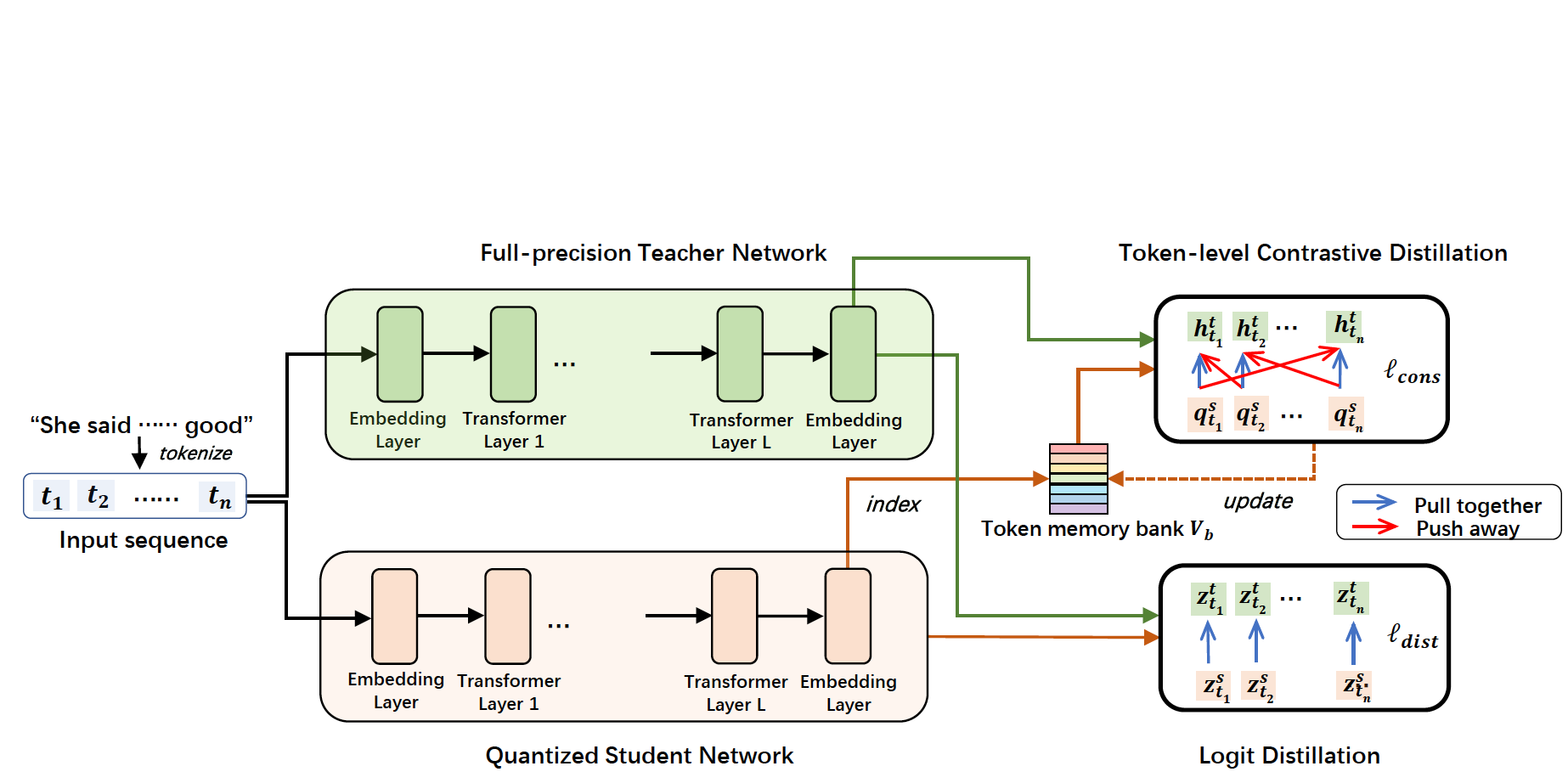
Chaofan Tao, Lu Hou, Wei Zhang, Lifeng Shang, Xin Jiang, Qun Liu, Ping Luo, Ngai Wong. Compression of Generative Pre-trained Language Models via Quantization, ACL-2022 (outstanding paper award) [PDF], [Blog(中文解读)] TL,DR: We firstly explore compressing generative PLMs (i.e. GPT-2, BART) by quantizing the parameters from full-precision to lower bits, and apply to language modeling/summarization/dialogue tasks.
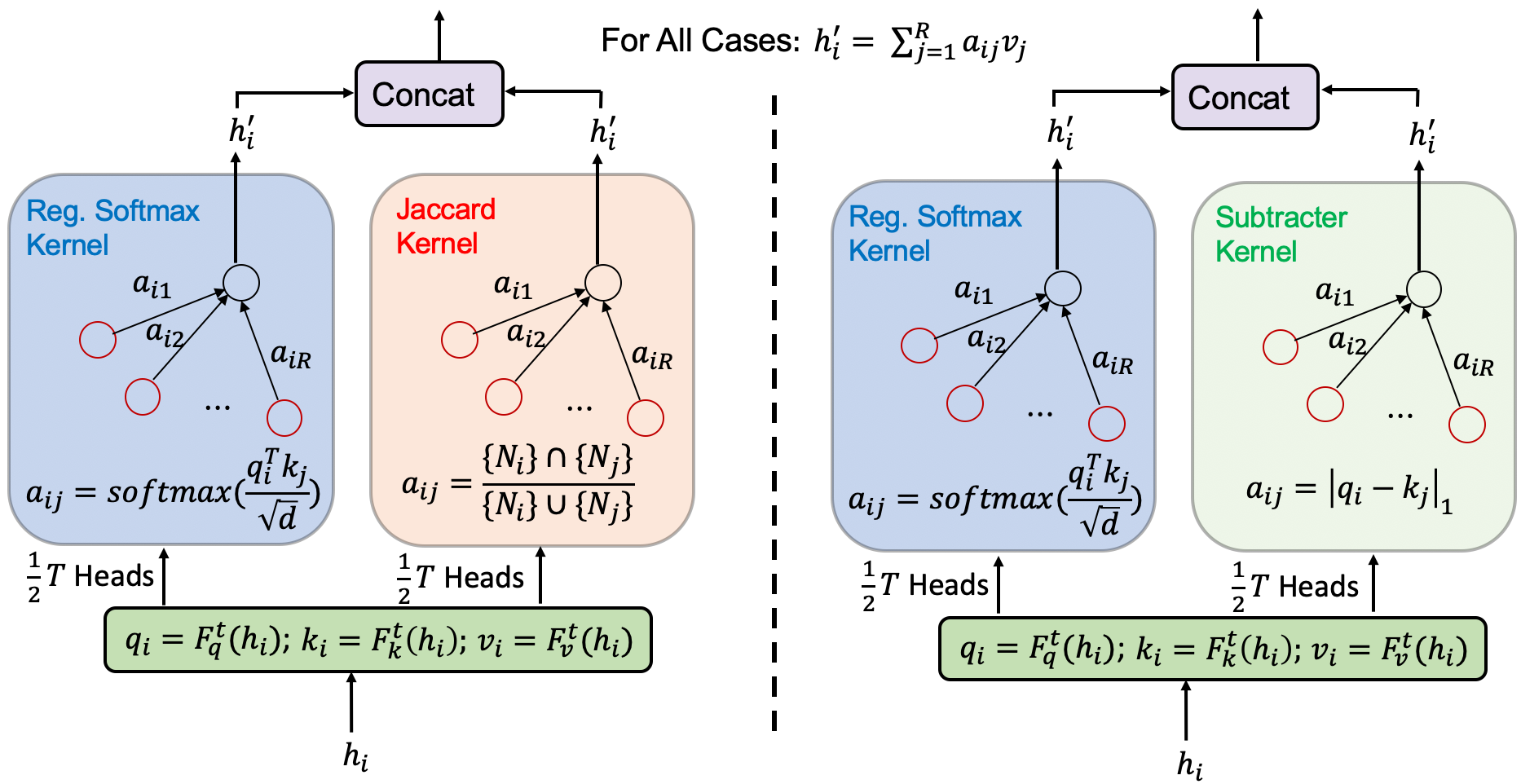
Cong Chen, Chaofan Tao and Ngai Wong. LiteGT: Efficient and Lightweight Graph Transformers, CIKM-2021 [PDF], [Code], [Video], TL,DR: LiteGT is an efficient learner on arbitrary graphs, which saves computation, memory and model size altogether.
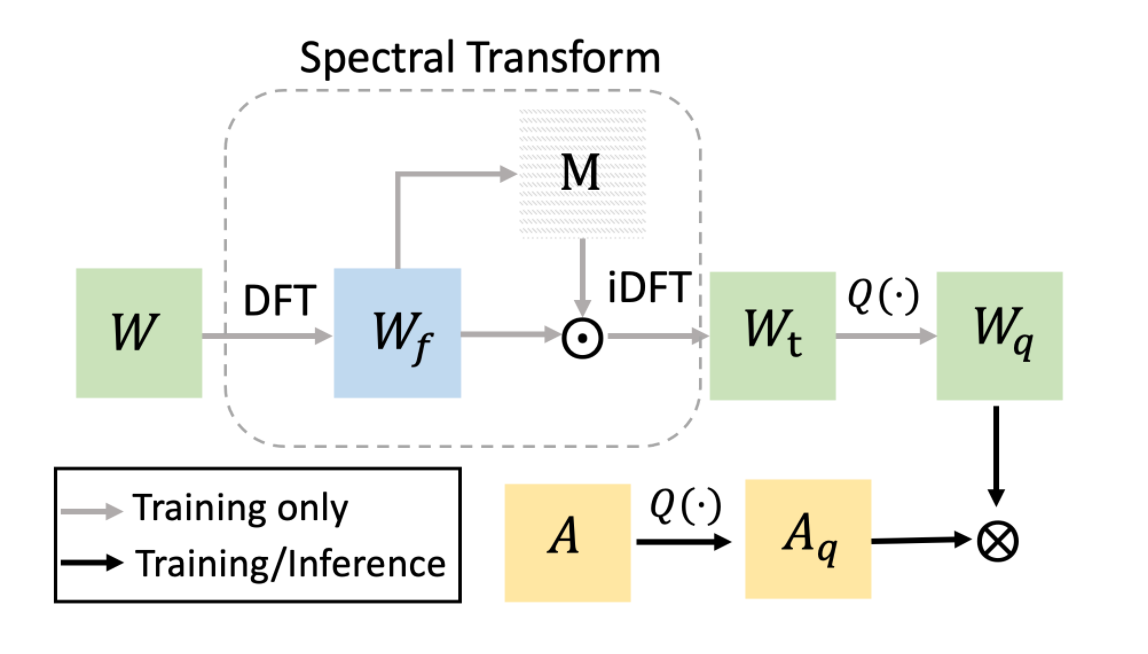
Chaofan Tao, Lin, Rui and Chen, Quan and Zhang, Zhaoyang and Luo, Ping and Wong, Ngai. FAT: Frequency-Aware Transformation for Bridging Full-Precision and Low-Precision Deep Representations, IEEE T-NNLS [PDF], [Code] TL,DR: FAT is a quantization method that models the task of quantization via a representation transform and a standard quantizer.
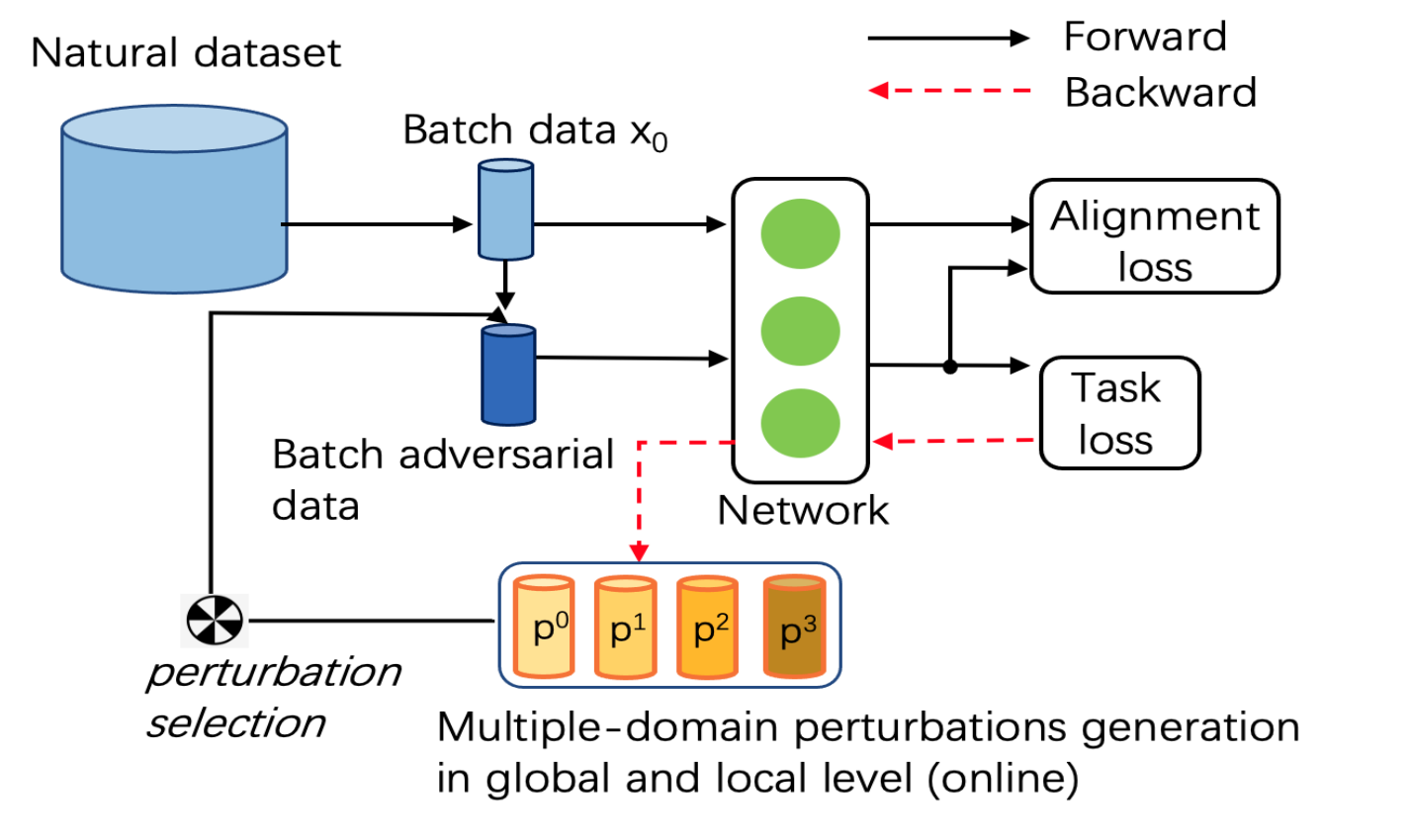 Chaofan Tao, Ngai Wong", ODG-Q: Robust Quantization via Online Domain Generalization, ICPR-2022 [PDF], TL,DR: We propose an efficient way to improve the robustness of quantized models on the large-scale datasets. </p>
Chaofan Tao, Ngai Wong", ODG-Q: Robust Quantization via Online Domain Generalization, ICPR-2022 [PDF], TL,DR: We propose an efficient way to improve the robustness of quantized models on the large-scale datasets. </p>
Chaofan Tao, Qinhong Jiang, Lixin Duan, and Ping Luo. Dynamic and Static Context-aware LSTM for Multi-agent Motion Prediction, ECCV-2020 [PDF], [Supplementary material], [Demo], [Cite] TL,DR: DSCMP is a multi-modal trajectory predictor that considers spatio-temporal interactions among agents and scene layout.
